自然语言理解(Natural Language Understanding, NLU)是NLP领域的一个分支,在自然语言理解的过程中,首先就是对意图(Intent)分类,然后接着对槽位(Slot)填充。
意图分类时一个典型的文本分类的问题,常用的方法如下:
- 基于规则的方法
用户人工定义一些匹配规则进行分类。 - 机器学习的方法
SVM, Decision Tree等等。 - 深度学习的方法
目前更加推崇使用 End-to-End 的网络进行分类。
最近收集了一些关于意图分类以及槽填充的相关的数据集以及对应的测试指标。
中文数据集
NLPCC 2018 Task4 - Spoken Language Understanding in Task-Oriented Dialogue Systems
数据描述 [1]
这个数据集来源于某车载产品的真实日志数据,主要涉及音乐,导航以及打电话等等领域,11种意图以及15种槽值类型。其中包括 5.8K 次会话,总共有 26K 次叙述(Utterance)。特别地,这个数据集仅仅包含了用户的输入(没有系统的回复),并且针对错误的槽值进行了修正,如将“什话”修正为“神话”。
- 训练集:4705次会话, 21352次叙述。
- 验证集:1177次会话, 5350次叙述。 (训练集:验证集 约 4:1)
数据格式1
2
3
4session ID 用户query 意图 语义槽标注
1 打电话 phone_call.make_a_phone_call 打电话
1 我想听美观 music.play 我想听<song>美观</song>
1 我想听什话 music.play 我想听<song>什话||神话</song>
评估方法
这个比赛主要有两个评估方法:
意图分类,评估方法为F1值,具体的计算方法如下:

意图分类以及槽填充,评估方法是准确度。即意图分类以及所有的槽位都完全正确。
主要算法
总共有16个队伍参加了这个比赛,但是只有两个队伍开源了他们的方法,分别是HLSTM-SLU模型和Sogou团队的模型。具体结果如下:
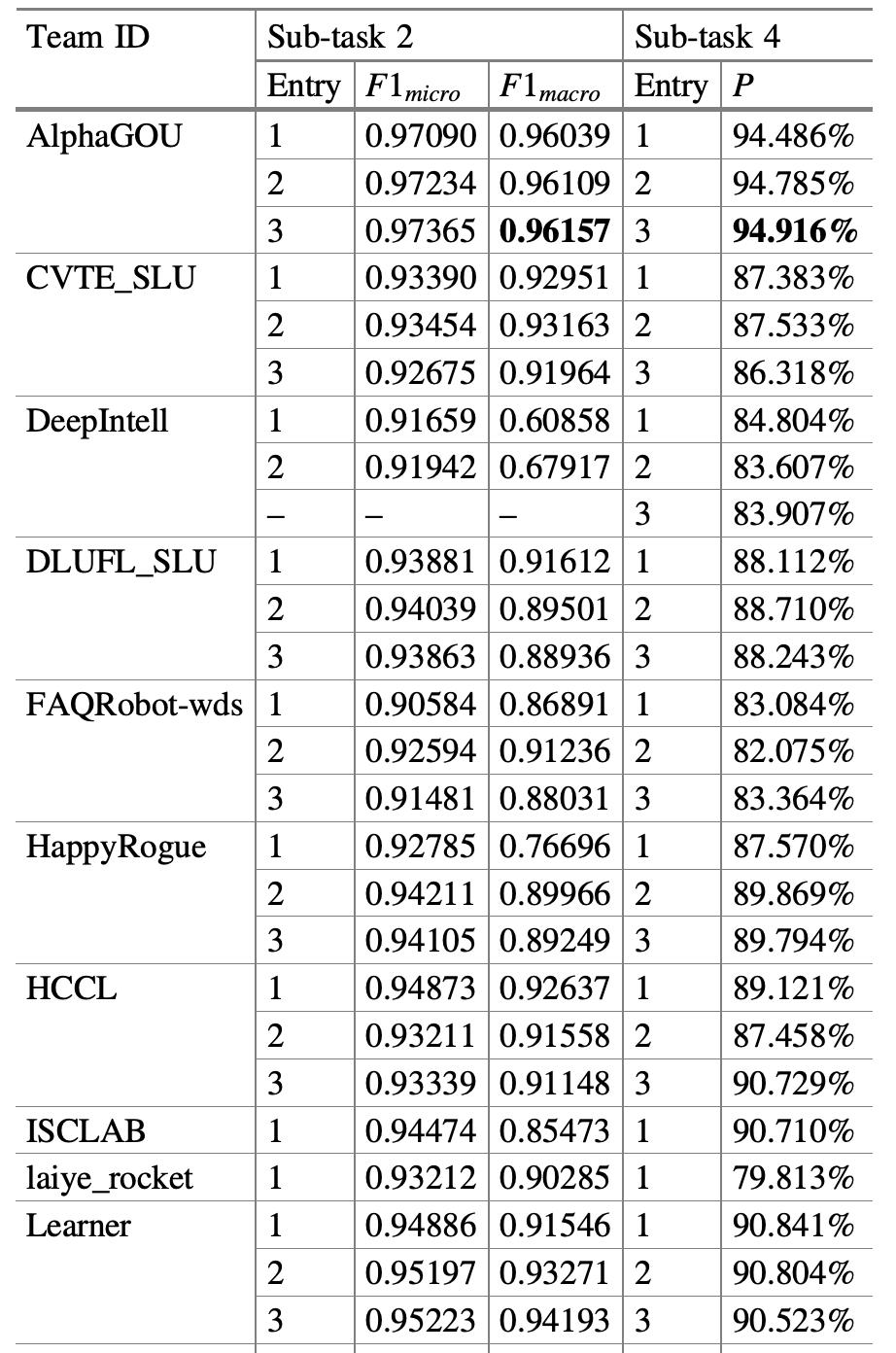
HLSTM-SLU [2]
这个可以看做是深度学习的方法和传统的机器学习方法相结合。模型结构如下:
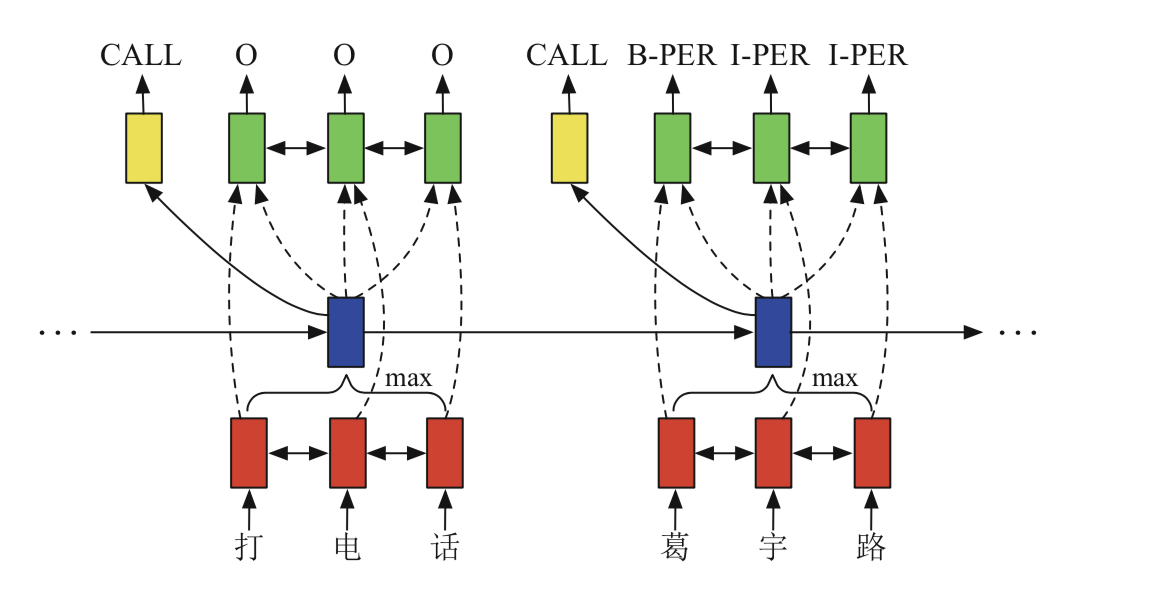
这个模型主要由三个LSTM组成,两个双向LSTM处理输入和输出,一个单向LSTM处理一个会话中的多个叙述。
- 输入Bi-LSTM
输入:Character Embedding + POS + Domain
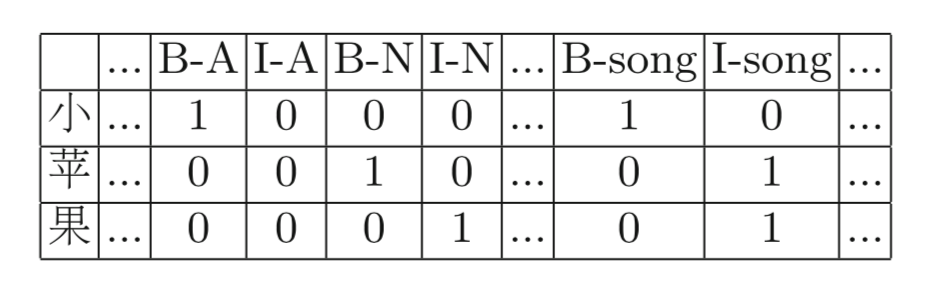
其中POS表示对每个字进行词性标注,并用类似于BI的方法进行编码;Domain表示不同领域的词,也用BI的方法进行编码,具体实例如下:
Session LSTM
输入:一次对话中的每轮的描述经过输入Bi-LSTM的输出经过最大池化之后的结果。
输出:意图的类别输出Bi-LSTM
输入:Session LSTM + 输入Bi-LSTM
输出:槽位标注
注:并没有直接使用LSTM的结果作为最终的结果,而是根据 CRF 预测最优的序列。
Trick: 使用 over sampling 解决意图类别中的样本不均衡的问题,并在过程中使用规则识别了一部分小样本的意图。
结果:这个模型在两个评估方法的结果最终为94.19%,90.84%。
Sogou [3]
这个模型没有使用深度学习的方法,而是使用传统的机器学习中的序列标注方法。首先,他们认为用户的query可以根据是否有显性的意图词分为两类(这一部分主要根据实体词匹配算法得到)。对于有显性意图词语的query,采用基于规则的处理的方法进行标注;剩下的部分采用基于模型的方法,具体的模型方法分为5步:
对query进行分词和词性标注(POS)。
寻找槽边界:先对处理后的query使用character embedding + word embedding; 根据BILOU原则,使用CRF对其进行序列标注。
槽分类:根据槽边界检测结果的character embedding + word embedding以及词性标注结果POS,通过逻辑回归的方式(Logistic Regression)进行分类。
槽修正:若槽类别预测错误,则根据词之间的相似性寻找真实槽类别中的所有的值与之进行相似度比较,进而修正结果。
意图分类:使用XGBoost的方法,根据word embedding,query长度,槽类别进行意图分类。
注:由于训练样本比较少,针对模型预测错误的数据,他们根据比较query与Sogou语音中最匹配的进行替换,最终针对意图分类增加了500个数据,槽填充增加了1000个数据。
结果:这个模型在两个评估方法的结果最终为96.11%,94.49%。
英文数据集
Frame
数据描述 [4]
这个数据集主要针对航班和酒店预订,来源于基于Wizard-of-Oz(WOz)设定的人机对话的过程(实际上是一个人假扮机器)。其中包括 1369 个对话, 总共有 19986 轮。
数据格式
每一次叙述都包含 ‘author’, ‘text’, ‘labels’, ‘timestamp’, ‘frames’(‘frame id’, ‘frame parent id’, ‘requests, binary questions, compare requests’, ‘info’), ‘db’字段。其中 ‘labels’记录当前的active_frame以及对话过程中的Act(包括act名称以及对应的slot类型和值), ‘info’字段主要为了标注对于槽位值是否为否定的。
Act类型:inform, offer, request, switch frame, suggest, no result, thankyou, goodbye…..
评估方法
微软在提出这个数据集的同时,也定义了一个任务Frame Tracking,这个任务与State Tracking不同的是,它可以同时追踪一个frame与之前几轮相关的frame,以及由一个frame转变到多个frame,例如用户要求系统可以推荐4个符合条件的旅行,如下图所示:
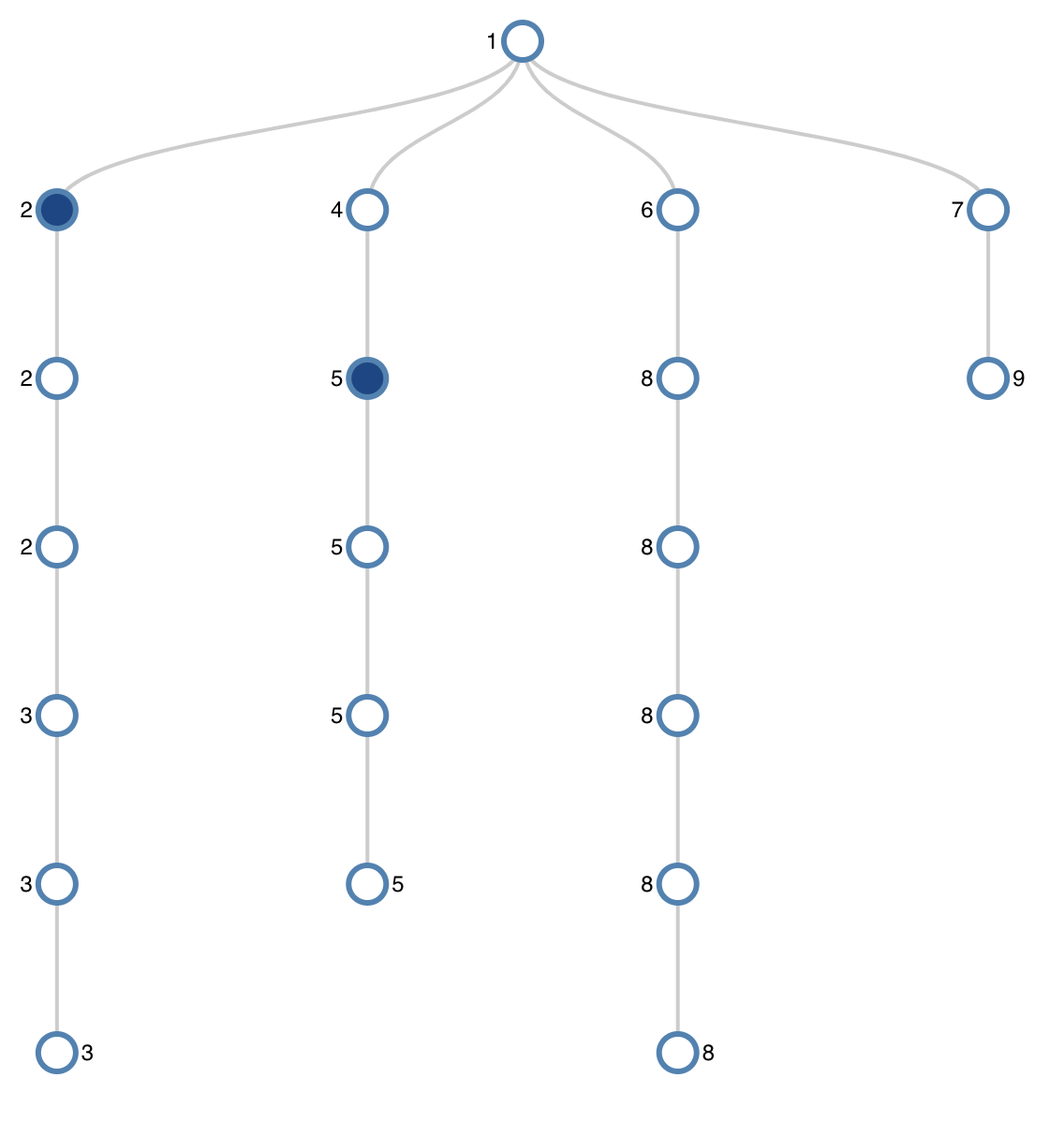
这个任务就是需要预测是否有新的frame生成。如果有,则预测其目的Act,限制条件Ref Labels以及之前相关的Frame ID,如果预测结果完全匹配,则认为预测正确,最后计算准确度。同时计算总的预测有新的frame生成的叙述个数,计算其识别新frame生成的准确度。
主要算法
Baseline [4]
由下图可知模型结构,针对叙述中的每个词,将其表示为trigrams的形式,然后通过一个embedding层,tanh激活层。针对Act分类和Slot分类,分别用一个双向的GRU实现,输入为每个词在激活层的输出。最后经由一个softmax分类层得到最终的类别。
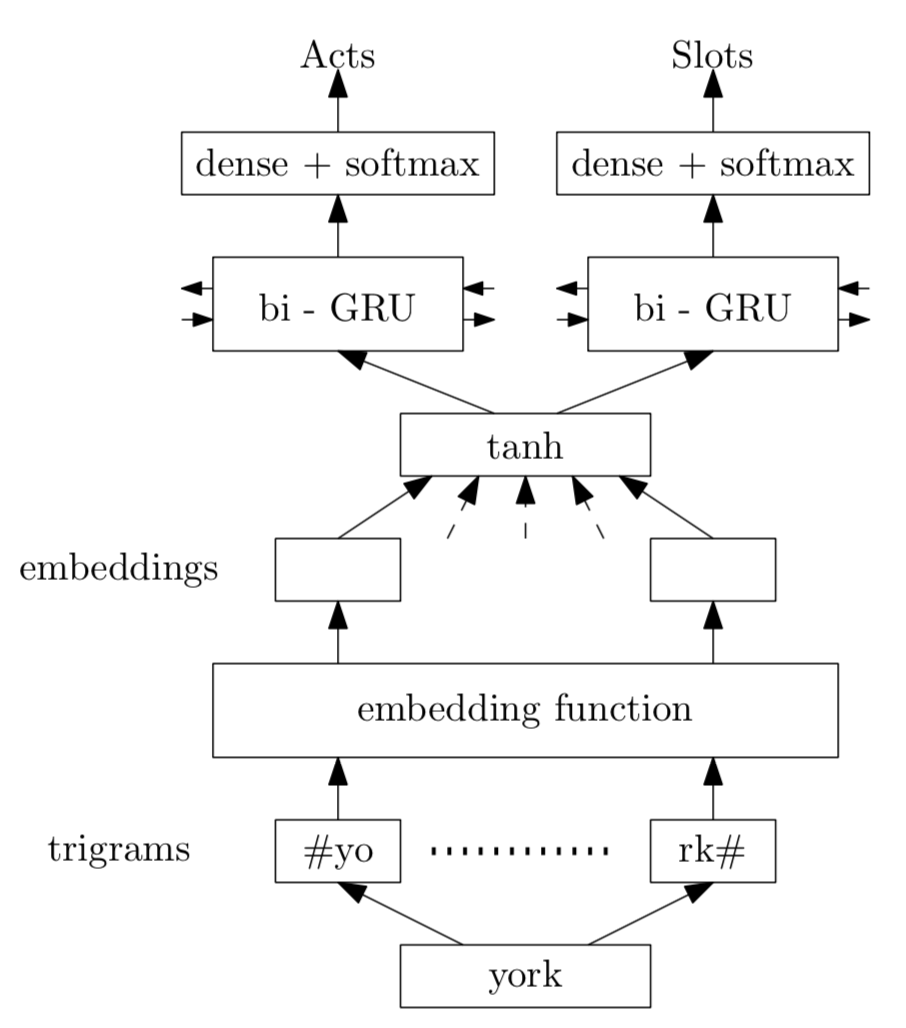
结果:这个模型在两个评估方法的结果最终为:frame识别准确度0.24 ± 0.02, frame新建识别准确度为0.49 ± 0.03。
Frame Tracking Model for Memory-Enhanced Dialogue Systems [5]
微软的团队随后提出了一个新的模型来处理这个问题。
输入预处理
Token Encoding:每个词用trigrams的形式表示。如:“hello” -> #he, hel, ell, llo, lo#。构建trigrams词典D-T,每个词都表示为(Trigrams ID)。
用户叙述:将叙述中的每个词用trigrams的形式表示,这些trigrams经过一个embedding层,输出的向量的和来表示这个token,再经过一个 Bidirectional GRU,将所有的隐层状态堆叠起来来表示此轮的叙述。
Frame:每个frame由槽类型Slot和槽值Value组成,与trigrams类似,分别构建槽类型词典D-S和槽值词典D-V。即,每个frame表示为(Slot ID, Token ID)。
Act:每个act由行动类型Act,槽类型Slot和槽值Value组成。即,每个act表示为(Act ID, Slot ID, Token ID)。
模型输入
当前轮之前所有的frames (Slot ID, Trigrams ID)
叙述 (Trigrams ID)
当前轮对应的行动Act (Act ID, Slot ID, Trigrams ID)
模型结构
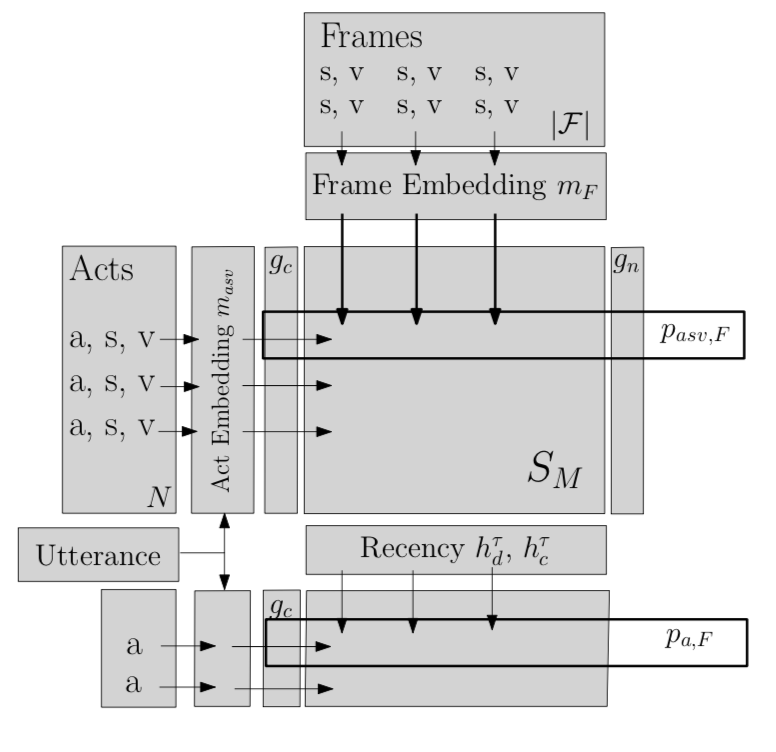
对于frames,(Slot, Token)经过一个GRU,将隐层其映射为一个256维的向量,所有的隐层堆叠起来表示最终的frames,\(m_f\) (|F| * 256);对于act,将(Act, Slot, Token)输入一个 Bidirectional GRU,将隐层以及叙述embedding连接起来,并将其映射为 \(m_{asv}\) (N * 256, N为act的数量)来表示acts;
通过计算 \(m_f\) 和 \(m_{asv}\) 的点乘的结果 \(S_m\) (N * |F|)来表示act和frame之间的相似性,也可以看做基于frame的一个多项分布。特别地,他们还事先根据act中的槽值与frame之间的槽值的相似性计算了act与frame之间的相似性 \(S_L\) 。最终,根据两者的线性组合来表示act与frame之间的相似性 S。
在用户新输入一个(act, slot, value)表示时,根据这个相似矩阵可以得到一个多项分布\(p_{asv, f}\) ,从而得到与之相关的frames,从而也就得到了他们实验的衡量指标之一,基于槽分类slot的frame追踪。
另外,对于每一个(act,frame)对,他们会根据输入的act, 以及用户的叙述经过两个全连接层得到最终的 \(p_{a, f}\) ,从而也就得到了他们实验的另一个衡量指标,基于行动act的frame追踪。
注:这里没有详细介绍实验的一些完善trick,如模型图中的\(g_c\), \(g_n\), \(h_d\), \(h_c\),详情请看论文。
结果:这个模型在基于槽分类的准确度为76.43 ± 4.49,基于行动Act分类的准确度为95.66 ± 2.34。
DSTC (Dialog State Tracking Challenge) [6, 7]
数据描述
DSTC 是针对一系列的对话数据,完成对话跟踪的任务。也就是针对每一个数据集,意在可以根据之前的状态来预测新的对话的状态。目前DSTC数据已经更新到DSCT6,下面将简单介绍各个版本的数据。
DSTC 1
这个数据集包括城市BUS的预定电话中的对话数据。12963轮训练数据,2485轮测试数据。DSTC 2&3
在DSTC 1的基础上,增加了关于餐厅,旅游信息等等相关的对话。其中DSTC2包括2218轮训练数据,1117轮测试数据;DSTC3包括3235轮训练数据,2275轮测试数据。数据中的semantics字段会对对话中的槽slot和目的act标注。下面是一个数据样例:1
2
3
4
5
6
7DSTC2 and DSTC3 (Training Set)
SYS: Which part of town?
USR: The north uh area
SYS: Which part of town?
USR: A cheap place in the north
SYS: Clown cafe is a cheap restaurant in the north part of town. USR: Do you have any others like that?
SYS: Galleria is another cheap restaurant in the north. USR: What is their phone number and address?DSTC 4
这个数据集是人与人之间关于旅游信息的对话数据,其中有一个子任务Spoken language understanding,意在给每个叙述中的目的acts和语义槽slots打标签。挑战赛总共收到了5个提交模型[7],其中最好的结果的F1值约为0.52。其中三个模型分别为:- SVM分类模型
输入:叙述的unigrams, bigrams, trigrams,标签(标注当前叙述与上一个叙述是否为同一个人) - 逻辑回归模型
输入:同上。 - 随机森林模型
输入:问题数目,标签(标注当前叙述与上一个叙述是否为同一个人),标签(标注当前叙述与上上一个叙述是否为同一个人),标签(标注这个人是导游还是旅客)
- SVM分类模型
DSTC 5
这个数据集针对跨语言测量,也就是训练集为英语数据,测试集为中文数据。DSTC 6
这个数据集关注在多轮对话,其任务包括端到端的目标导向的对话学习,端到端会话建模,以及对话故障检测。
评估方法 (DSTC2 & 3)
- 准确度:正确预测的轮数占数据总轮数的百分数。
- L2距离:向量1为正确预测的轮标为1,其余为0组成的向量;向量2为根据模型得到的每一个的概率值组成的向量,计算向量之间的距离。
主要算法
这里我们主要关注在DSTC3上的四个模型。
马尔科夫判别模型 [8]
这是来自中科院声学与语言理解研究所的一个模型。为了能够支持未知的领域,因此这篇文章将通过假设每一轮的可能的域来动态的更新分类的类别。
$$ Y_t^s = Y_{t-1}^s + H_t^s$$,其中\(H_t^s\)是在t轮对于槽类型s的假设的集合。
另外,也是本文中比较新的一点是马尔科夫判别模型,也就是将生成模型和判别模型相结合:
生成模型: \(P(S_t) = k \sum_{S_{t-1} \in S} P(O^t | S_t) P(S_t | S_{t-1}) P(S_t) \)
判别模型: \(P(S_t | O_1^t) = f(O_1^t)\)
马尔科夫判别模型:\((P(S_t | O_1^t) = \sum_{S_{t-1} \in S} P(S_t | O_1^t, S_{t-1}) P( S_{t-1} | O_1^{t-1})\)
在训练过程中,由于当前叙述之前所有的标签都是已知的,而预测过程中之前的都是预测的结果,这会导致训练的模型会过度依赖状态转移矩阵,这个问题称作标签过耦合问题。为了解决这个问题,他们设计了一个2步训练法:
第一步:训练一个传统的判别模型。
第二部:在第一步的基础上训练状态转移特征。
这样第一步预测的错误会在一定程度上解耦相邻的状态直接的联系。最终这个模型在准确度和L2距离的结果分别为0.576,0.652。
循环神经网络 [9]
这个模型的注重点在于模型对扩展域的自适应性的问题(即训练数据中不存在的槽类型即槽值)。其中,系统将用户叙述中的槽类型和槽值分别用<slot>和<value>来替代。由于对于每个叙述表示的都是在不同的槽类型和槽值之间的概率分布,因此若一个新的叙述的概率分布与系统的已知的叙述中的概率分布类似,则可以认为两者具有类似的的槽类型和槽值的关系。
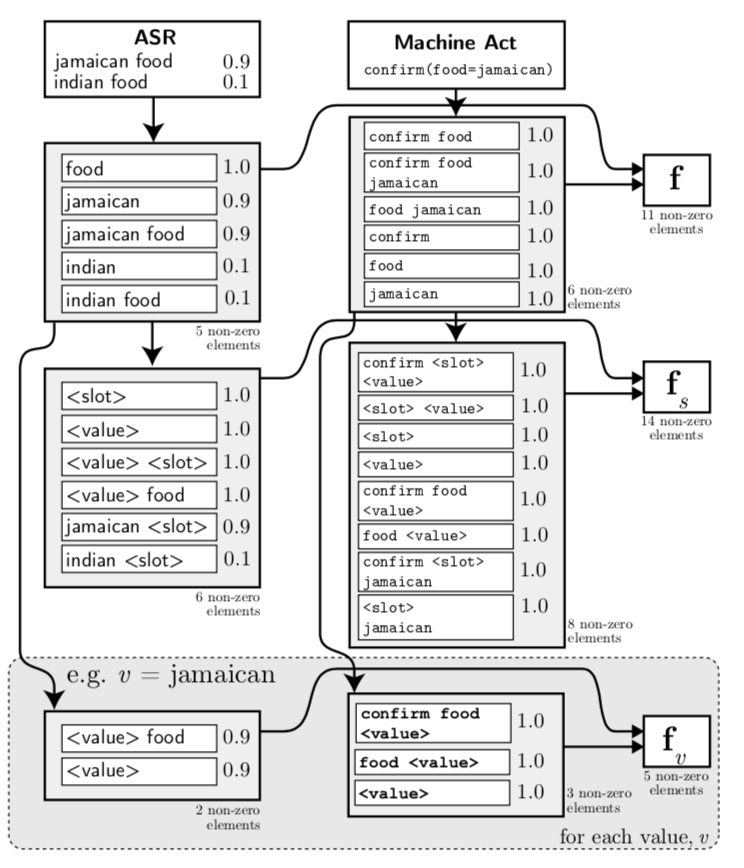
通过上图的过程,我们可以得出 “Jamaican food”标记为 “s=food and v=jamaican”,若新的叙述为 “The Girton area” 其替换为<slot>和<value>的概率分布与前者类似,因此可以得出 “s=area and v=girton”。最终这个模型在准确度和L2距离的结果分别为0.646,0.534。
基于规则的模型 [10]
这篇文章设定了很多推理规则,并将规则看做是满足某些线性约束的特殊类型的多项式函数,马尔可夫贝叶斯多项式 (Markov Bayesian Polynomial, MBP)。在某些假设下,这个模型的求解过程可被视为整数线性规划问题 (Integer Linear Programming, ILP),实验证明其具有很好的泛化能力。最终这个模型在准确度和L2距离的结果分别为0.610,0.556。
知识驱动的基于规则的模型 [11]
这篇文章认为目前的语言理解模型无法识别用户不关注的点,以及一些易产生歧义的信息,因此他们提出了一种基于知识的方法。对于每轮叙述,会基于机器的上一个动作act,用户的acts以及之前的act的概率分布猜想生成新的用户目标的概率分布猜想,类似于一个演绎推理的过程。最终这个模型在准确度和L2距离的结果分别为0.630,0.627。
[1] Overview of the NLPCC 2018 Shared Task: Spoken Language Understanding in Task-Oriented Dialog Systems
[2] Learning Dialogue History for Spoken Language Understanding.
[3] The Sogou Spoken Language Understanding System for the NLPCC 2018 Evaluation.
[4] Frames: A Corpus for Adding Memory to Goal-Oriented Dialogue Systems.
[5] A Frame Tracking Model for Memory-Enhanced Dialogue Systems.
[6] The Dialog State Tracking Challenge Series: A Review, Learning End-To-End Goal-oriented Dialog.
[7] Adobe-MIT submission to the DSTC 4 Spoken Language Understanding pilot task.
[8] Markovian discriminative modeling for cross-domain dialog state tracking.
[9] Robust Dialog State Tracking Using Delexicalised Recurrent Neural Networks and Unsupervised Adaptation.
[10] A generalized rule based tracker for dialogue state tracking.
[11] Knowledge-based dialog state tracking.