面向任务的对话(Task-oriented Dialog)主要关注在某些特定的领域,用户带有目的的发起的会话。本文将从一个具体的数据集出发,结合基于此数据集设计的不同的系统来具体的分析对于此类任务的the-State-of-Art。
数据集 In-Car DataSet
数据集 In-Car DataSet,是用户和车载助手对于日程安排,天气和导航三个领域进行的多轮对话,下面是一个对话例子:
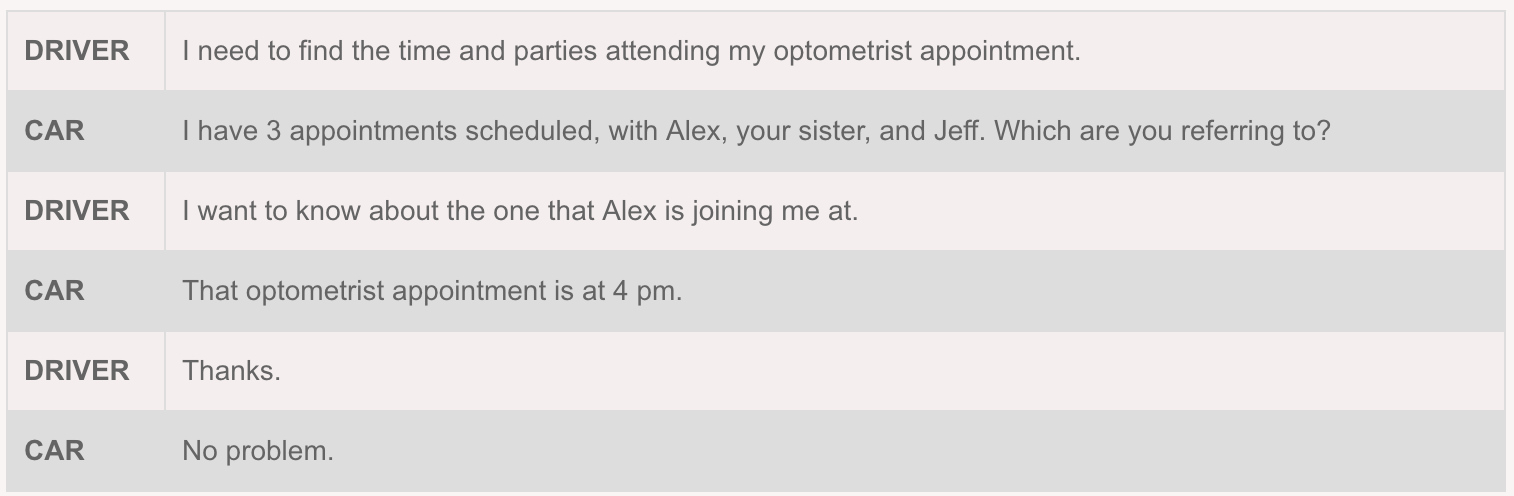
这个数据集中总共有3031次对话,具体信息如下:

其中针对3个不同的领域,日程安排,天气和导航,具有不同的槽类型以及槽值:

特别地,此数据中认为后台已经有一个知识库(Knowledge Base)。即用户提出请求后,系统会在这个知识库中找到匹配的答案,最终生成相应的答案。下面是两个基于此数据集的对话系统。
Key Value Retrieval Networks [1]
这个模型是针对此数据集提出的 baseline,将End-to-End模型与信息检索模型结合。
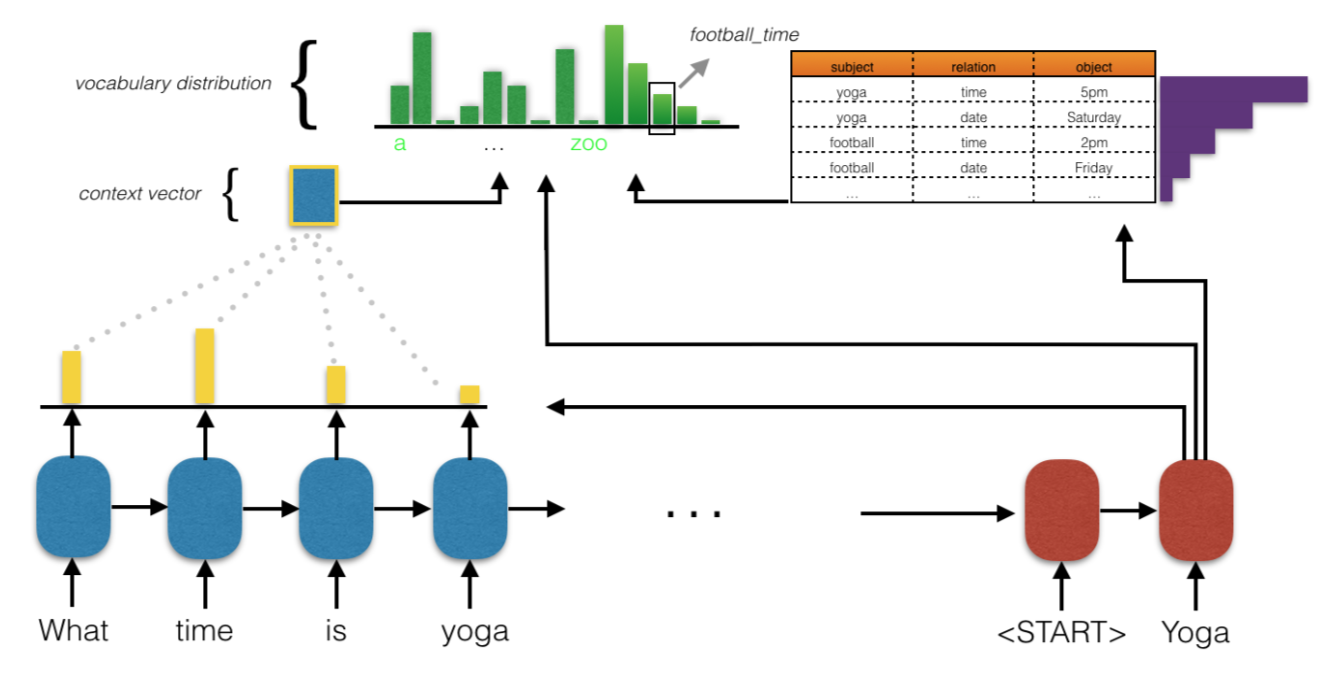
Encoder - LSTM
输入:历史对话,\((u_1, s_1, …, s_{i-1}, u_i)\)
Hidden State: \(h_i\)Decoder
输入:\(h_i\)
Hidden State: \(\tilde{h_{t}}\)
输出:\(y_1, y_2, …, y_n\)
其中,在decoder的过程中,结合了Attention机制,来给知识库中不同的KB entry给予不同的权重。Attention
在知识库(Knowledege)中,每个entry表示为(subject, relation, objective)。在模型中,将每个entry表示为subject和relation的embedding的和\(k_j\)。具体的attention计算过程如下:
\[u_i^t = w^T tanh(W_2 tanh(W_1[h_i, \tilde{h_{t}}]))\] \[a_i^t = softmax(u_i^t)\]\[\tilde{h_{t}}^{,} = a_i^t h_i\]\[u_j^t = r^T tanh(W_2 tanh(W_1[k_j, \tilde{h_{t}}]))\]\[o_t = U[\tilde{h_{t}}, \tilde{h_{t}}^{,}] + \tilde{v_{t}}\]\[y_t = Softmax(o_t)\]
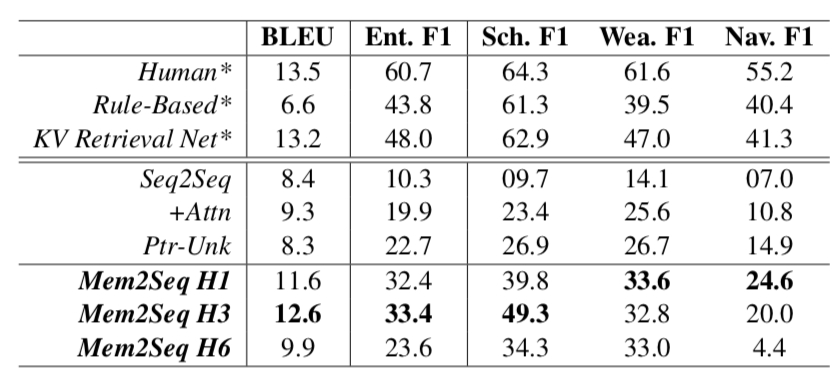
其中,\(\tilde{v_t}\)维度为|V| + n,|V|为词典长度,n表示为指知识库中entry的个数。需要特别注意的是,本文通过NER将知识库中具体的“槽值”替换为“槽类型”(如,“5pm”替换为“meeting_time”),这样就使得词典的长度大大减少。\(\tilde{v_t}\)中与知识库中相关的表示为\(u_j^t\),其与为0,即加重网络在知识库上的权重。总的来说,我们可以将\(v_t\)看做是分别在原始词典和知识库上的概率分布,通过两者来确定最终的输出。最终的实验结果如下:

Mem2Seq [2]
这篇文章主要结合End-to-End memory network和Pointer network的思想。其中MemNN是将memory和question进行embedding,然后计算两者的匹配度;接着对memory进行另一种embedding之后,以匹配度作为权重得到输出;再结合question,通过softmax得到最终的answer。而Pointer network没有关注在输出,而是通过计算encoder和decoder的匹配度之后,直接根据其softmax值指向输入的某个部分,从输入序列里“提取”一些元素来输出。
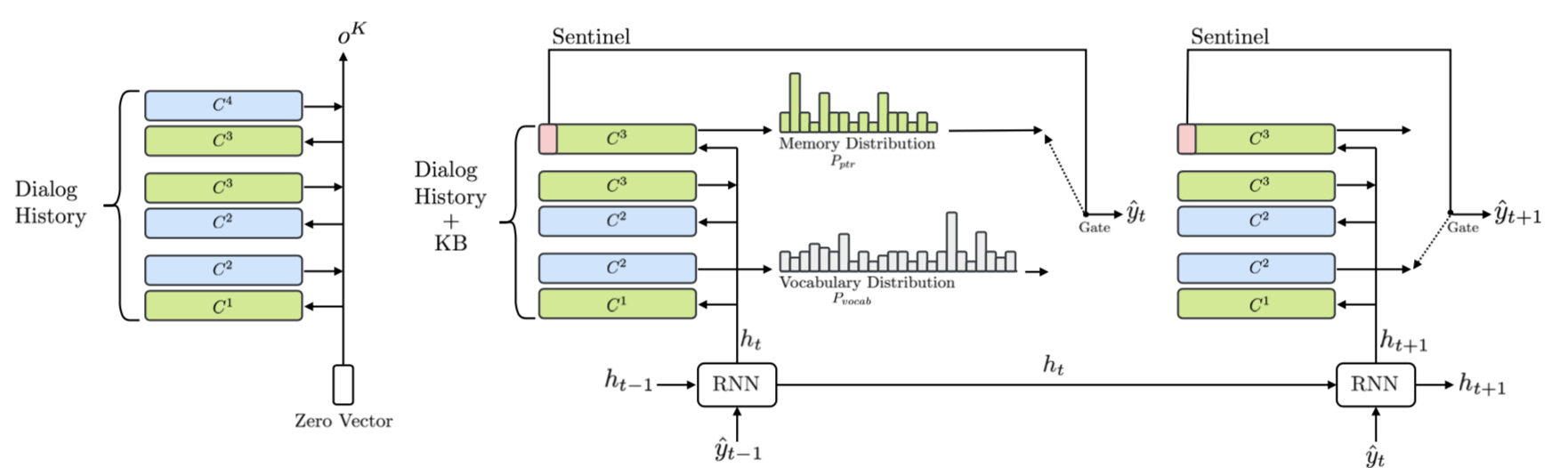
Encoder - Multi-hop MemNN
输入:U = [B; X],其中X = {x1, …, xn, \$} 为对话历史,包括时间信息和用户信息(如“hello”表示为“hello t1 \$u”),\$表示结束;B = {b1, …, bl}表示知识库。
输出:\(o_k\)\[ p_k^i = Softmax(q_k)^T C_i^k\] \[o_k = \sum p_k C_{k+1}\] \[q_{k+1} = q_k + o_k\]
一般的MemNN过程,其中\(C_i\)为Encoder的memory。
Decoder - GRU + MemNN
输入:\(o_k\)
HiddenState:\(h_t\)
输出:\(P_{vocab}(\hat{y_t}), P_{ptr}\)\[P_{vocab}(\hat{y_t}) = Softmax(W_1[h_t; o^1])\] \[P_{ptr} = p_t^K \]
其中,\(P_{vocab}(\hat{y_t})\)结合第一个hop的输出得到输出词在词典上的分布,\(P_{ptr}\)是Decoder中MemNN的最后一个hop的\(p_t^K\)表示(此处K=3),可以看做是在对话历史和知识库上的分布。当生成的词为“\$”时,则从词典中选择词语作为输出,否则则在对话历史或者知识库中选择词作为输出。最终的实验结果如下:
下面是一个具体的生成案例:
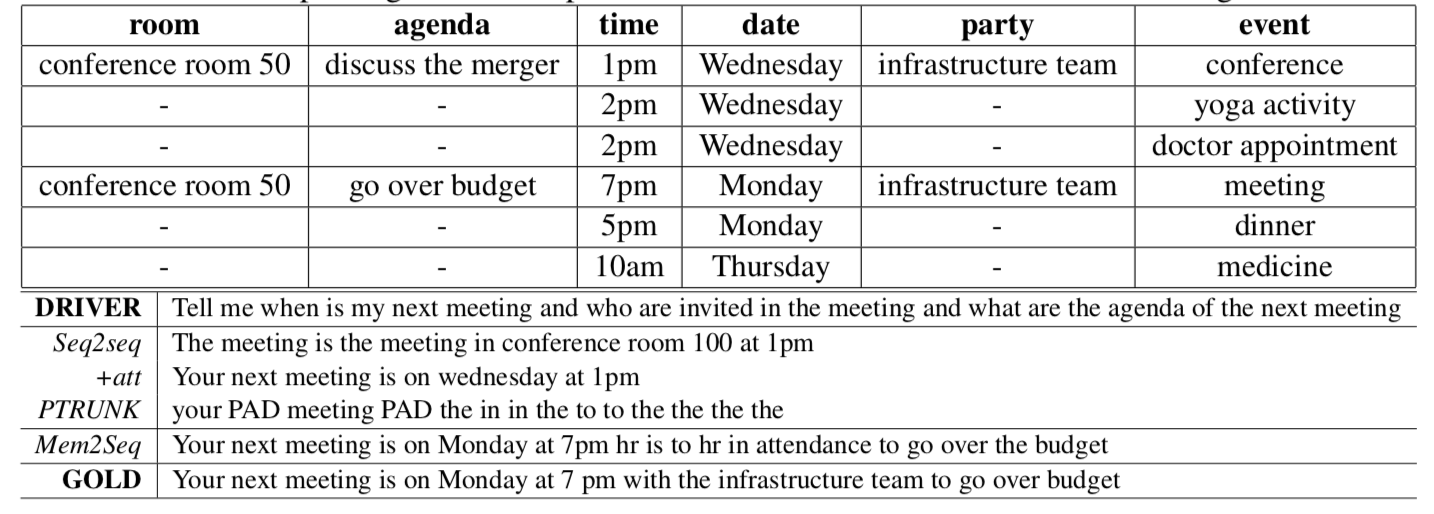
[1] Key-Value Retrieval Networks for Task-Oriented Dialogue.
[2] Mem2Seq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Systems.