意图识别 (Intent Classification) 和 槽位填充 (Slot Filling) 是自然语言理解 (Natural Language Understanding, NLU) 领域常见的两个子任务。意图识别可以看作一个分类任务,槽位填充则是一个序列标注问题,之前的模型往往是基于这两个任务构建两个模型来分别处理。最近提出了很多意图分类和槽位填充的联合学习模型,结合两个任务之间的依赖关系,提高了模型的效果。
1. Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
这篇论文可以看做是联合训练模型的 Baseline,很多新提出的模型的结果都会与之对比。模型的主要结构是基于 Attention 的 Encoder-Decoder 结构,其中 Encoder 是双向RNN,Decoder 是单向RNN ,具体模型结构图如下:
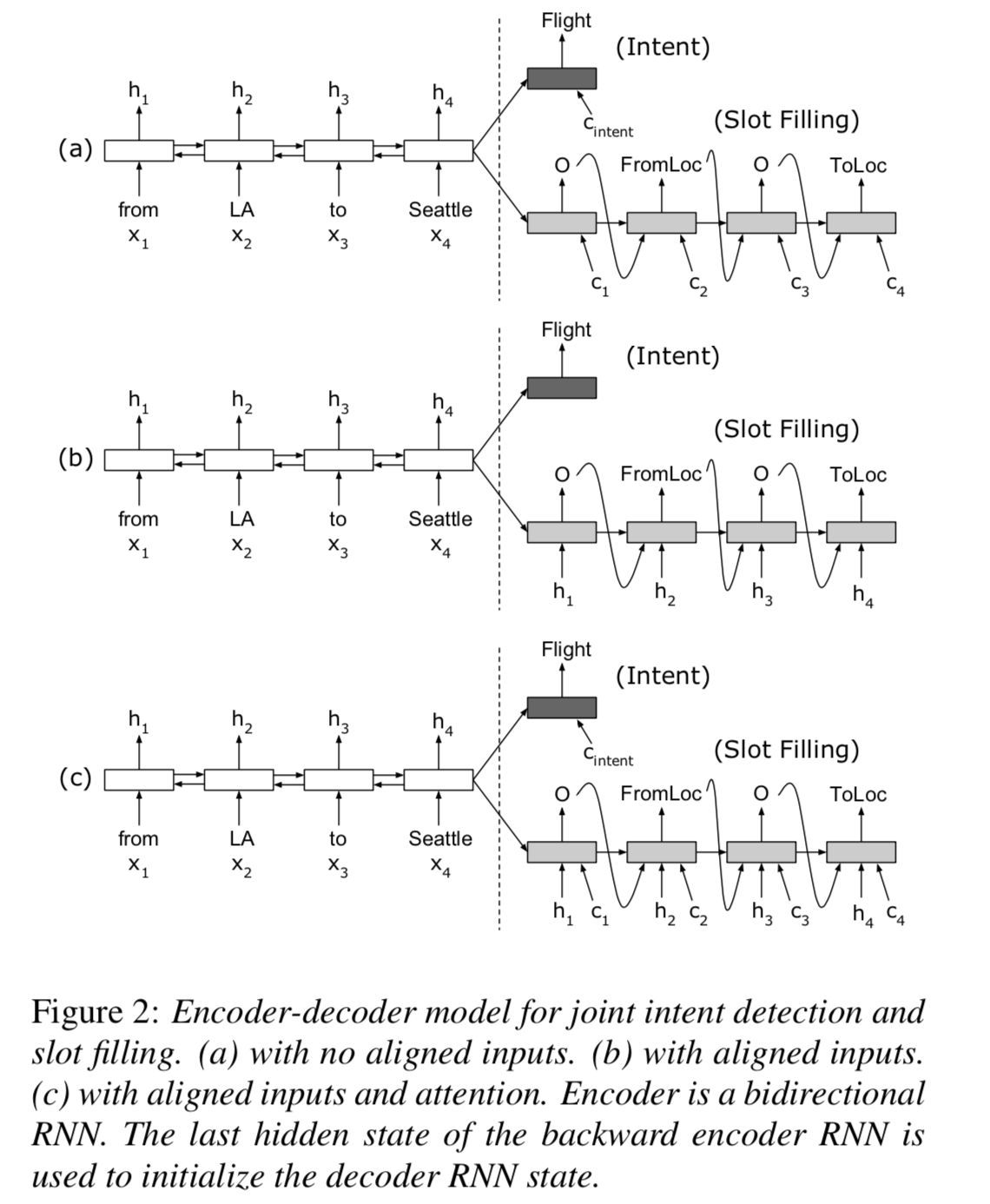
输入经过 Embedding 层之后经过 Encoder,其中序列最后一个的 hidden state 用来进行意图识别,同时作为 Decoder 的输入,Decoder 的每一个隐层结合 Attention 信息一起进行槽位填充。其中 Attention 的计算如下:
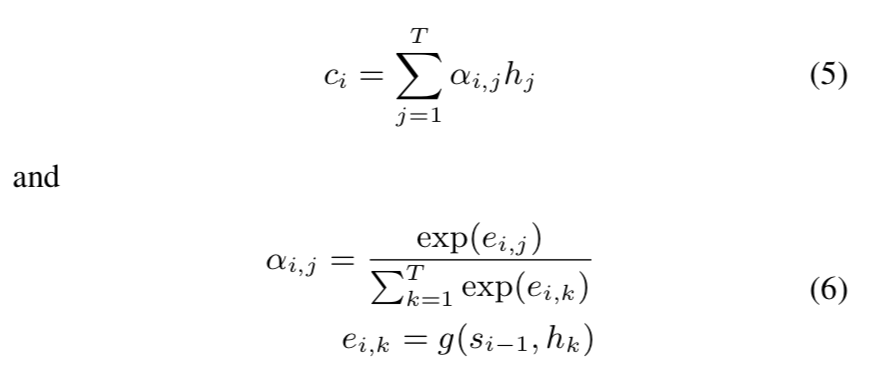
2. A Deep Learning Based Multi-task Ensemble Model for Intent Detection and Slot Filling in Spoken Language Understanding
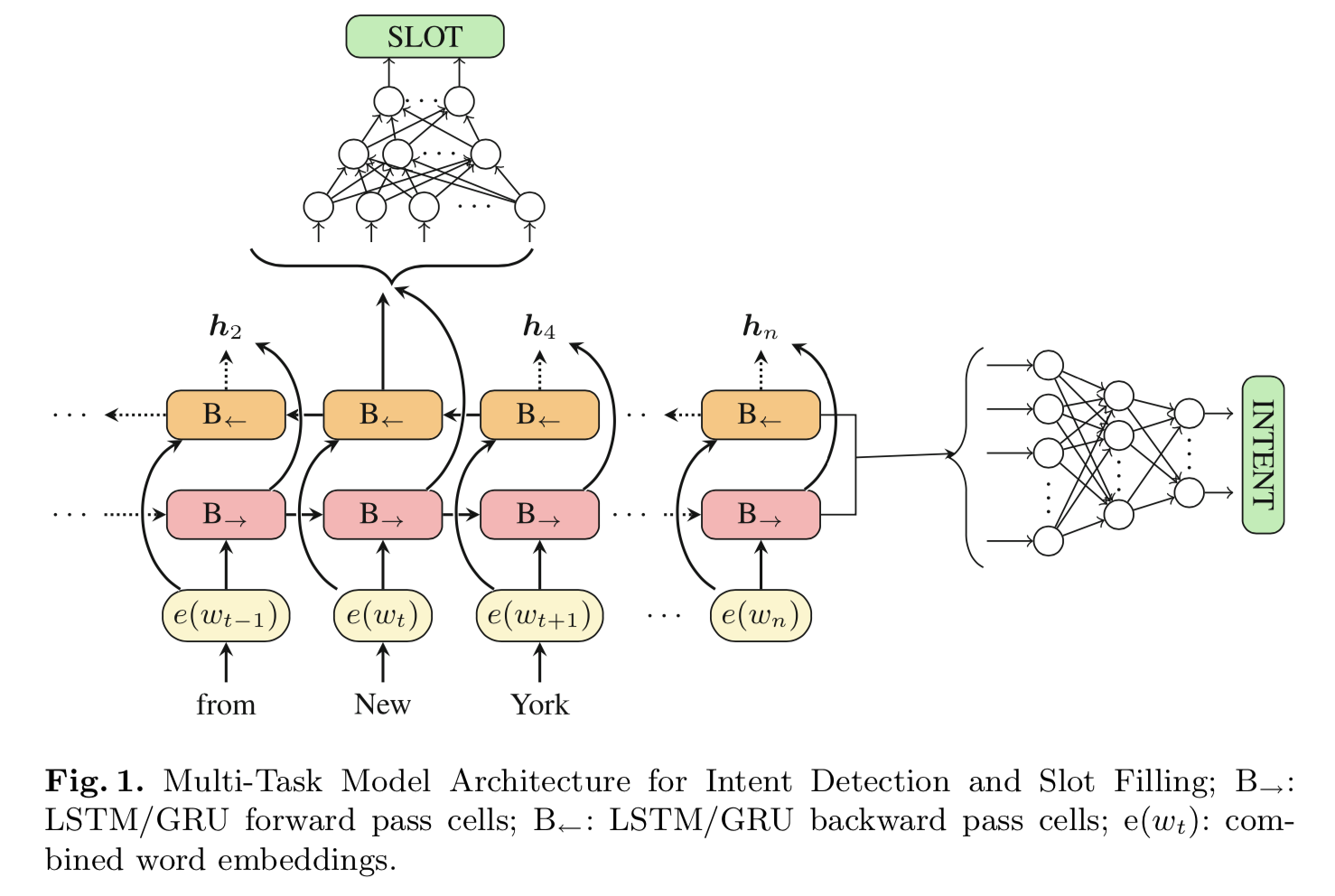
这篇论文对于输入的处理同样是双向 RNN。对于意图识别和槽位填充两个任务构建了两个分离的 MLP 分别训练,但是反向传播的过程中两者的结果都会影响 RNN 的参数。模型细节如下:
- 将 Word2Vec 和 GloVe 合在一起作为词语的 Embedding 输入RNN;
- 模型使用两个RNN,Bi-LSTM 和 Bi-GRU 分别处理输入,然后将结果合在一起(Ensemble)作为 MLP 的输入;
- 引入 词性信息POS 和 RNN 的结果拼接在一起作为 MLP 的输入。
3. Unsupervised Transfer Learning for Spoken Language Understanding in Intelligent Agents
这是一篇AAAI 2019的论文,主要是使用了语言模型 ELMo 进行在大量没有标签的数据上进行预训练,然后 Transfer Learning 之后得到了比较好的效果。论文通过实验说明了在进行预训练之后使用 1k 条有标签数据 Fine-tuning 之后的结果与使用 10k-15k 条有标签数据从头开始的结果相当。模型细节如下:
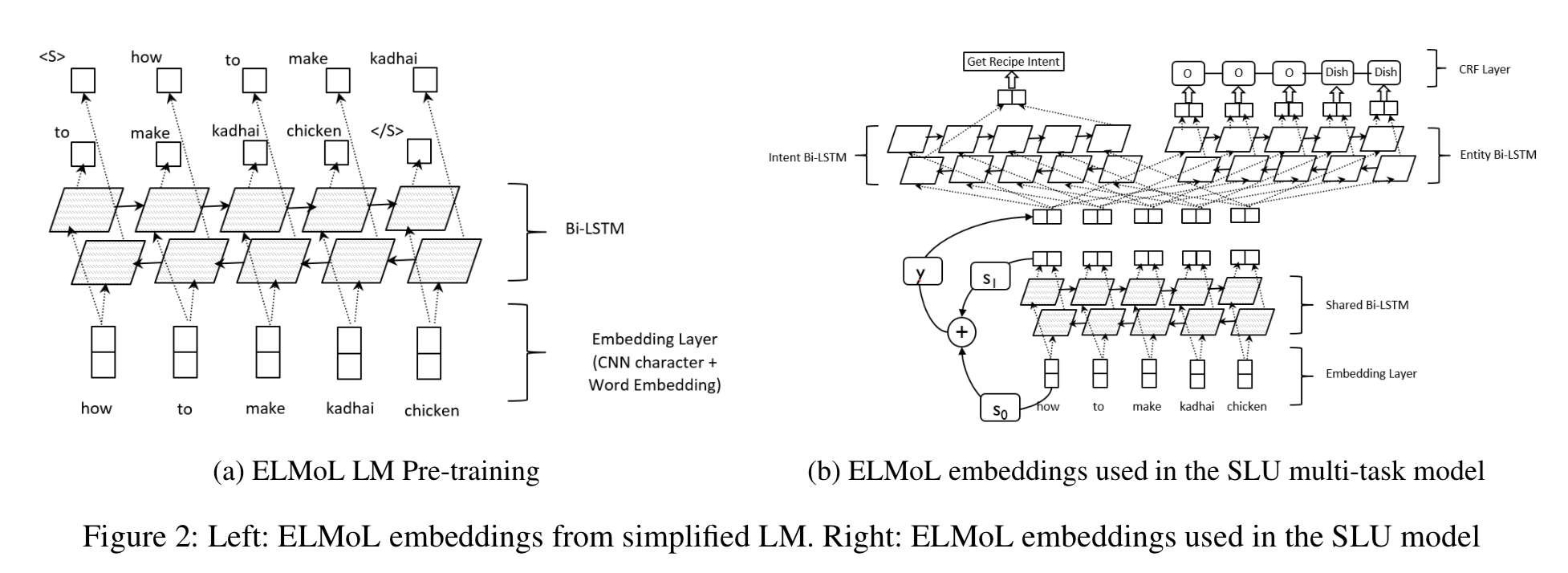
由于对话场景中的语料一般是比较简短的,没有必要使用原始的模型结构,论文中的 ELMoL 是简化了 ELMo 后的结构,只用了一层的 Bi-LSTM。在语言模型训练好之后,移除前面的 CNN 层只保留最后的这层 Bi-LSTM 和 与意图识别和槽位填充相关的模型结构一起进行训练。同样地,对于意图识别和槽位填充也是两个分离的 Bi-LSTM,并在最后接上了一个 CRF 用于槽位填充。
在模型训练过程中使用的trick:
- Gradual Unfreezing:先开始仅更新顶层的参数而不改变较低层(靠近语言模型)的参数。
- Triangular Learning Rate:三角学习率是指学习率先升后降,先开始比较小的学习率可以防止参数向错误方向进行更新。
- Discriminative Fine Tuning:不同的层使用不同的学习率进行更新(较低层学习率较小)。
4. A Bi-model based RNN Semantic Frame Parsing Model for Intent Detection and Slot Filling
这是一篇NAACL 2018的论文。之前的文章基本都是使用同一个 Bi-RNN 来对输入进行处理,这篇文章最大的不同是使用了两个 Bi-RNN 都对输入进行处理,但是这两个 Bi-RNN 不是分离的而是通过共享 Hidden State 相互关联的,模型细节如下:
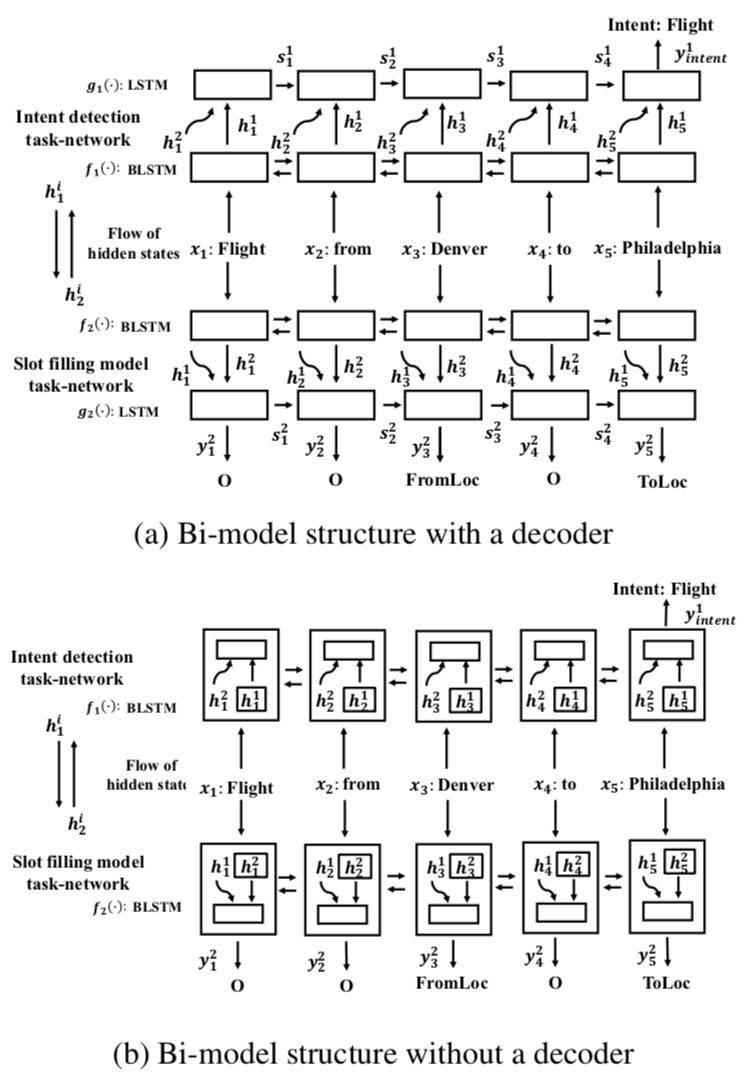
图中有两个模型,不同点在于意图识别和槽位填充都分别增加了一个 LSTM 来进行解码,其他地方相同。可以看到:
- 用于意图识别的 Bi-RNN 的 Hidden State \(h^1\) 会输入到用于槽位填充的 Bi-RNN 跟 \(h^2\) 一起作为 RNN 单元的整个的 Hidden State 进行迭代;
- 同样地,用于槽位填充的 Bi-RNN 的 Hidden State \(h^2\) 也会输入到用于意图识别的 Bi-RNN 跟 \(h^1\) 一起作为 RNN 单元的整个的 Hidden State 进行迭代。
所以模型训练是异步进行的,也就是首先进行意图识别的训练得到一组 \(h^1\),然后以同样的输入和这组 \(h^1\) 得到 \(h^2\)。
5. BERT for Joint Intent Classification and Slot Filling
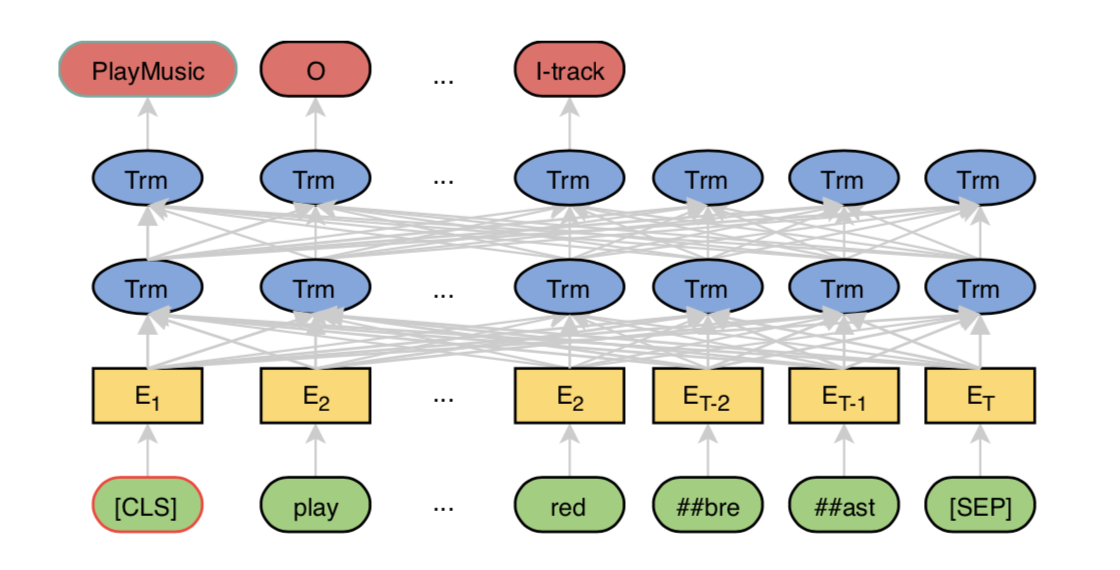
BERT 既可以用于分类问题,也可以用于序列标注问题,这篇文章是 BERT 在意图识别和槽位填充上的一个应用。文章模型中的意图识别部分继续沿用了 BERT 的 [CLS] 部分进行分类,槽位填充除了直接用输出进行序列标注之外还在上面接了一层 CRF(通过实验结果发现 CRF 的影响并不大)。
其中需要注意的是 BERT 使用了 WordPiece 对词语进行处理(可能一个词会被拆成多个sub-token,如 “redbreast” -> “##red”, “##bre”, “##ast”),文章使用这些 sub-token 中的第一个(这里是 “##red” )对应的模型的输出进行预测。模型细节如下:
6. 不同模型在 ATIS 数据上的结果
| Model | Intent Accuracy | Slot F1 |
|---|---|---|
| Attention BiRNN | 98.21 | 95.98 |
| BiRNN(Ensemble) & MLP & POS | 98.43 | 98.07 |
| ELMo & Bi-LSTM & CRF | 97.42 | 95.62 |
| Bi-model with a decoder | 98.99 | 96.89 |
| BERT | 98.60 | 97.00 |